Loudness and normalization
Understanding what is loudness, how it's measured and why standards exist.
The history of loudness
Loudness is a term used to describe how loud a time window in an audio track is perceived. This isn’t always tied to how much volume a signal has, as signals that are some decibels quieter than others, may sound louder than a signal whose absolute level is higher. Sounds difficult? We know.
The human ear senses signals differently from a measurement device. The human ear’s frequency response changes depending on sound pressure level, flattening as 100 dB closes in. Dynamics also play a crucial role in how loud a sound is perceived. Less dynamic range tricks our brain into thinking “this is loud”.
From as early as 1940’s, the perceived loudness was tried to get as high as ever possible, but thanks to the technology back then, not much could be done. One example of a recording that was “too hot” was the Led Zeppelin II, which actually caused some LP players cartridges to jump out of the groove. This served as a good point that shouldn’t be exceeded until a new, more forgiving delivery method could be used.
In the 1980’s, music producers noticed that people tend to think a track sounds better when it sounds louder. Naturally, everyone wanted to sound better, and now that a digital delivery medium was available, mixing and mastering engineers began pushing the levels higher and higher. But from the digital realm, another issue was to rise. A digital media can’t have a signal that’s louder than -0 dBFS. Now everyone was again hitting the same limitations, and the war of volume couldn’t progress.
Coming to the 90’s, mixing engineers had had time to experiment, and had realized that if the signal sample peak couldn’t exceed -0 dBFS, the peaks must be taken down. This allowed the engineers to raise the overall levels, while keeping the peaks in control. This process is called limiting. Up until 1994, engineers were using analog limiters that weren’t as surgical as what was coming. In 1994, Waves launched the first digital brick-wall limiter that had a magical feature: lookahead. This feature “knew” in advance what kinds of peaks were coming in the next milliseconds, and limited the audio before the peak occurred. This gave the engineers yet another chance to push the audio even closer to the magical threshold of -0 dBFS.
The years between the end of 90’s and the start of 2000’s mark the point where loudness war became a norm — everyone had become accustomed to the exceptionally loud tracks that if a track actually had any dynamics left, it “sounded bad”, because it wasn’t perceived as loud.
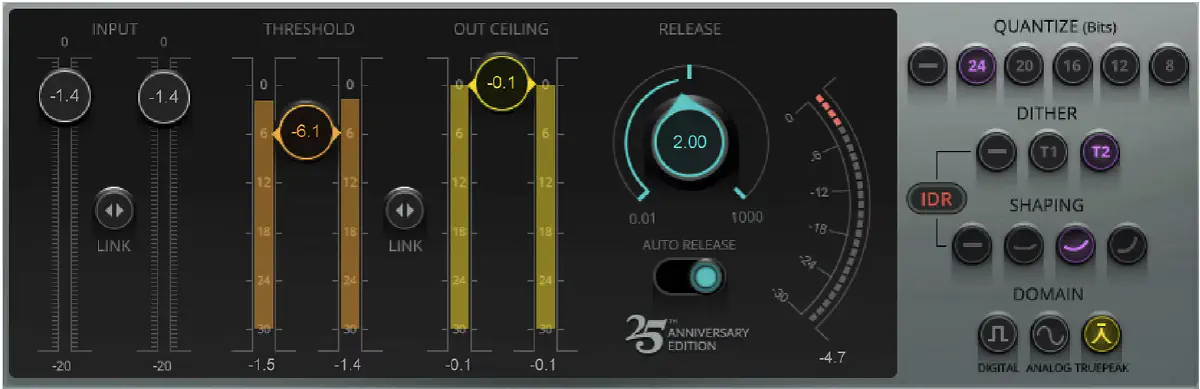
What actually happens when the loudness increases?
The process that leads into a louder audio is essentially restricting the dynamic range: the loudest sounds are artificially taken down so that the overall level can be taken higher.
You could think of it this way: you are the music track, and if you’re lucky enough to have a table in your kitchen, the space between that table and the floor below shall be the delivery media. Let’s imagine the table is as tall as you are. Now you’re standing below the table, just so that the top of your head barely touches the tabletop from below. You, the music track, are at full height (full dynamic range). This is fine, unless the audience wants to hear louder tracks, which, unfortunately, they do. You try to lift yourself onto your toes, but hit your head (you’re clipping now). Then you realize that if you reduced (limited) your height (the dynamic range), you could appear to be standing higher (appear louder), but you’d just occupy less vertical space (less dynamic range). Do this until you’re squashed against the table top from below, and feel like you can’t breathe anymore. That’s how the music track feels.
The point in limiting is not to take the overall level any higher, that’s not possible anymore. Instead, as we learned from the example, the point is making the apparent lowest level be higher than the competitors. This reduction in vertical space occupied is called limiting, and it results in a narrower dynamic range, where whispers are almost as loud as a scream.
Why are squashed dynamics a bad thing then?
It isn’t, until you listen to more than one album. Everyone has their own vision on what’s the correct loudness, thus making it virtually impossible for all recordings being the same level. The European Broadcasting Union implemented a standard, based on ITU BS.1770, which sets target levels for perceived loudness, measured in LUFS (more of this later on). In the USA, the corresponding standard is ATSC A/85. These two make sure that in television and radio, the audio content will all be played on a level that results in an integrated loudness of -23 for EU, of -24 LUFS in USA. This doesn’t restrict the actual signal level except for a safety limiter at -1 dBTP. Why? Because now that everything’s compressed, the RMS or peak value doesn’t tell much about the actual loudness.
Digital streaming services also implemented their own standards based on the same R128 and A/85 were based on, but because they’re special, all of them have different targets for their loudness normalization.
How to measure something that’s based on perception
It isn’t a very simple process, and I’m not trying to make it one. However, to give an idea of what it consists of, the process makes use of signal processing methods to emphasize sounds that the human ear tends to hear more, and similarly doesn’t give much weight to the sounds we don’t hear that well. The resulting unit is LU, which stands for Loudness Unit (someone with a very vivid imagination was hired to come up with that name). LU is relative to dB in terms of change in audio level, meaning the difference between -10 LU and -12 LU is exactly the same as the difference between -10 dB and -12 dB. LU on the other hand is NOT equivalent to dB when it comes to absolute values — -10 dB rarely means -10 LUFS.
FS stands for Full Scale, borrowed from dBFS. Like dBFS, LUFS is anchored to the digital ceiling — -0 LUFS represents the maximum loudness achievable without clipping. In digital audio, -0 dBFS is the largest signal value that can be represented without distortion, and LUFS inherits this constraint as its reference point.
All sorts of peaks
The other abbreviation, TP, doesn’t stand for toilet paper, but stands for True Peak. Sounds like something from an ad, but is really something far more important. We’ve used the words Sample Peak and True Peak in this text, and it’s important to recognize these are not the same thing. However, to truly understand what these are, and why are they different, we need to jump into digital audio sampling theory for a little, because in analog audio, there are just peaks.
What makes up digital audio
For an in-depth explanation of the audio sampling theory, check this article about bit depth in digital audio.
When an analog audio signal is translated into digital signal, two concepts play an important part in making the digital representation be as accurate as possible. Sample rate represents the amount of audio samples in a second. Bit depth represents the amount of bits in one sample. The most common sample rate is 44.1 kHz. It means the audio is sampled 44.100 times in a second. It may sound a lot, but it’s just the lowest rate we can actually use to digitally reproduce the full human hearing spectrum. The Nyquist theorem tells us that the maximum frequency in a digital reproduction is the sample rate divided by two. Since we humans can hear up until 20 kHz, 40 kHz is the lowest rate that would suffice, however the technology back then had already something else in mind: the common 44.1 kHz rate comes from the end of the 70’s, from a Sony PCM adaptor, that wrote audio to video cassette tapes at the rate of 44.1 kHz. This specific sample rate worked with PAL and NTSC formats, where audio was stored to a cassette tape in multiple lines, and 44100 happened to be divisible by the line counts in both formats. Higher sample rates are used in recording and master delivery, and nowadays streaming services are offering the higher sample rates for Hi-Fi -subscribers.
Now that we have 44.100 samples of an audio track of one second, we need to dwell deeper into one sample. There would be no point in storing audio using only one bit. That wouldn’t provide nowhere near enough values. Instead, we use a minimum of 16 bits to present the analog audio accurately enough. A simple equation tells us this results in possible values to represent the current sample’s position in the amplitude. Remember, sample rate defines the granularity over time, and bit depth defines the granularity in one point of time over amplitude.
Taking the bit depth calculation result further, we get the accuracy in decibels . 16 bits can represent a dynamic range of 96 decibels. For delivery, this is often enough, but for recording higher values are required since 96 dB isn’t that much when recording real instruments. A bit depth of 24 bits is used to represent the dynamic range even better, giving us decibels to work with.
The peaks are hiding
Since you’ve not fallen asleep, I’ll finally tell you why all this matters. Since we’ve found a way to record analog audio well enough to store its peaks, there’s also a high chance we’ll be reproducing them. But since it’s digital, we’ll eventually miss some peaks that occur in between sample points. These peaks that happen in between samples are called inter-sample peaks. A limiter that limits sample peak will happily let these pass, until they reach the listener and cause distortion.
Another analogy: You check on your kid every hour. They drink between checks. When they finally emerge, they’re wasted. Inter-sample peaks work the same way — limiters that only check at sample points miss what happens in between.
A great way to make sure the peaks don’t have a chance to occur, is to increase the checking period. This is done by oversampling the audio usually four times, so that the little samples don’t have a chance of peaking anymore. A true peak limiter is exactly like this: it keeps an all-seeing superpower-eye on the samples, and limits when it catches even the tiniest peak.
Tying it all down with normalization
Normalization is the step where the gain from the loudness war goes down the drain. You could master the tracks to as loud as -8 LUFS, just to see it turned down by 15 dB (which is 18% of the original amplitude)
. In the process you have just lost lots of dynamics, and sound exactly as loud as everyone else.
There are two reasons for normalization. The most common method (peak normalization) comes from the technical constraints of playback devices, and the other (loudness-based normalization), which has in the past years become very common, comes from pure human enjoyment point of view.
Types of normalization
Peak normalization prevents any sample from exceeding -0 dBFS, avoiding digital clipping that occurs when values exceed the maximum representable number. When this number is exceeded, any values that exceed -0 dBFS will be clipped down to exactly -0 dBFS, resulting in clipping.
Loudness-based normalization then, on the other hand, is done for listener enjoyment. Some could argue this is done just for compliance theater, but we have to remember what the standards are there for. Without the loudness standards the users would have to turn their volume up and down between every song, or even worse, they listen to a jazz song, and after that comes a pop song that is ten decibels louder. This will cause at least discomfort, if not hearing damage. This normalization method will usually result in tracks playing out at a different volume when measured with non-LUFS-metering device. Tracks will sound equally loud though.
Another normalization method, which is not as common as the two previous methods, is RMS-normalization. This method has the same basic concept as peak-normalization, except that it uses a root mean square of the audio. RMS-normalization was used historically when loudness-based normalization wasn’t still very common. Its purpose was to normalize based on average energy content rather than short peaks.
In some DAW’s you could see a normalization option when bouncing the file, but what this usually does is either prevents clipping (only take down if the highest TP is over -0 dBTP) or a simple normalization (either boost or attenuate so that the loudest part is exactly -0 dBTP).
Normalization in practice
We briefly visited normalization before when talking about EBU and ATSC, and this one’s really simple. After we’ve done all the calculation and processing, we need to use that information for something. We know that we need to reach the target of -23 LUFS for R128 standard, and we also know our track is -18 LUFS. Normalization is the step where we apply gain, either negative (attenuation) or positive (boosting), to reach the target level. In this example we simply apply a 5 dB attenuation to the track.
It’s important to note that normalization does not alter the dynamics in any way. Normalization is a constant that is applied to the whole track instead of a short passage, like dynamic (real-time) normalization would. A compressor (or a limiter) can be used to prevent clipping, but using one will often increase the loudness, rendering it unusable for controlling loudness in a manner that satisfies the standards.
Sometimes normalization happens only at the playback state, so that the audio file remains untouched. This is called non-destructive normalization. The process includes analyzing the audio file, but instead of applying gain to it, we write a metadata field that tells the audio player if the track needs attenuation or boosting. Our TNT software handles both workflows perfectly. These tags, called ReplayGain tags aren’t read by all music players, so this works best for professional workflows where we know the tags will be of use, like broadcasting. Our A26 reads these tags by default, and even writes them by itself if they’re not there.
Streaming services have set their own loudness targets. Some only attenuate, others will either attenuate or boost so that you always hit the target. Services targeted for Hi-Fi consumers will often allow you to disable normalization at least to some degree. Since neither the EBU R128 or the ATSC A/85 have no authority over streaming services, these services set targets to what they see the best. Below is a table for the most common loudness recommendations (in case of streaming services) and targets (in case of actual broadcasting or where standards are to be followed).
Hear it in practice
Here are three files that have been processed differently. Only the dynamics have been affected, though multi-band compression was used in some examples, which can affect the tonal balance.
Track 1
Track 2
Track 3
Ask yourself
The tracks are normalized all to EBU R128 (-23 LUFS, -1 dBTP), so that they play out equally loud. Pay attention to these aspects:
- which track sounds the loudest?
- which track sounds the best?
- which track had you turn up/down the volume?
- which track allows you to hear more unique elements in the track? For example, pay attention to different instruments, reverb tails, effects etc.
- which track feels fatiguing?
- which track feels most natural?
- There aren’t strictly right answers, and this isn’t about any track being worse or better. They represent three different mastering styles for three different platforms.
Since you probably have listened to the tracks, here are the expected answers. Again, not right, but expected answers.
The loudest track is either track 2 or 3, depending on what you’re listening with. If from an iPhone speaker, track three sounds the loudest. If on headphones, the loudest track could be track two. Even though they all are normalized to -23 LUFS, our ear picks the difference, or in this case, lack of dynamics.
Since all tracks were normalized to the same level, the loudness itself doesn’t dominate our evaluation abilities that much. The track with most dynamics wins this one on most cases.
If you listened these in order, you probably didn’t touch the volume between songs. If you listened them in inverse order, you raised volume on each song.
This is a complicated one. In theory, the compressed track allows you to hear more details, but masking could affect your ability to hear them so well. Usually you’ll end up hearing more details in the least-compressed version.
The tracks are fatiguing in order. The first track gives the ears a lot of chances to “rest” because the audio isn’t a continuous wall of sound.
The tracks are in order from the most natural to the least natural, in terms of accuracy compared to the original material.
What was different
- Opto: Teletronix LA-2A leveling amplifier
- FET: Drawmer 1978
- Limiter: digital TP limiter
- All tracks share these per-element processing features:
- Rhythm sum: compressor with a 4.1:1 ratio, gain reduction (GR) of about 2-3 dB. Slow attack, slow release.
- Vocal sum: opto compressor with 1.4:1 ratio, slow, GR of about 2 dB. FET compressor with 4.1:1, fast, GR about 3-5 dB.
Track 1
This track is what we hear more and more in the streaming services nowadays. Full dynamics, only reasonable processing. -23 LUFS.
Dynamics
Single-band opto compressor at 1.4:1, attack 150 ms, release 250 ms. GR approximately 1-2.5 dB.
Digital TP limiter, release 250 ms, GR ≈0.5 dB.
Equalization
Tube EQ, high-pass at 60 Hz, Low-pass at 16 kHz. Slight boost at 3 kHz, Q1.
Digital EQ: cut at 250 Hz, 2 dB, Q1.5, cut at 600 Hz, Q1.
Track 2
This track represents the sound of the end of 2010’s, when streaming services became the most popular way of consuming audio. -11 LUFS.
In addition to the previous processing, the following were added.
Dynamics
Digital multi-band compressor, GR of 2-4 dB per band. Four bands.
Digital TP limiter, pushed so that it acts more, GR about 3 dB total, fast attack and release. Independency 0%.
Soft clipping 10%.
Equalization
Dynamic EQ removing some frequencies that would’ve otherwise been boosted by the dynamics processing.
Track 3
This is a 2000’s CD master, or for some artists still in 2025, their streaming service master. -8 LUFS.
In addition to the Track 1 processing, and in place of Track 2 processing, the following were added.
Dynamics
More aggressive multiband limiting, fast, GR 4-6 dB.
Limiter pushed harder, and made faster. Independency 100%. GR approximately 3-6 dB. Transient shaping for low and low-mid bands.
Soft clipping 30%.
What?
Channel independency in dynamic processors means the channels are either linked to each others (0% independency), or the channels can limit without being affected by each other. Usually buys you an extra dB or two.
Soft clipping is a kind of distortion that’s intentionally added to the track to make it sound louder. This usually doesn’t show in LUFS readings, but tricks us into thinking the track is louder than it actually is.
Ratio n:1 in dynamic processing, specifically in compression means that for n decibels, the output level only rises 1 dB. In limiters the ratio would be ∞:1 (or 100:1 in some devices).
| Streaming service | Loudness target in LUFS | TP limit in dBTP | Type of normalization |
|---|---|---|---|
| Apple Music | -16 LUFS (± 1 LU) | -1 dBTP | Full, without limiting. In other words, boosts only if headroom allows. |
| Qobuz | None, streams actual master files, at actual mastering levels. | Can peak over -0 dBFS. | - |
| Tidal | -14 LUFS (± 1 LU) | -1 dBTP | Only attenuate, if applicable |
| Spotify | -14 LUFS | -1 dBTP | Full, if 'Loud' setting is on, also limits, though TP must not exceed -1 dBTP |
| Deezer | -15 LUFS (± 1 LU) | -1 dBTP | Only attenuate, if applicable |
| YouTube | -14 LUFS (± 1 LU) | -1 dBTP | Only attenuate, if applicable |
| TV/radio | -23 LUFS (± 1 LU) (EU), -24 LUFS (± 2 LU) (USA) | -1 dBTP (EU), -2 dBTP (USA) | Full |
| CD | - | -0.1 dBTP (though theoretically, -0 dBTP is possible) | Comes from the technical constraints of the delivery medium. |
How to avoid loudness penalty
Mix and master with your ears, check LUFS just for curiosity. Don’t try to achieve some magical LU target — it’ll just get turned down eventually, leaving you with less dynamic range and you’ll be just as loud as everyone else.
Crash course to decibels
What decibels actually are, why they're logarithmic, and what that means when you change a level by 3 dB.
Dynamic Score
Making decisions on automated dynamic range compression requires a scoring system that takes three different measurements into consideration.
Audio encoding artifacts
How audio encoders use psychoacoustic masking to reduce file sizes, and why this process creates audible artifacts in compressed formats.
Loudness and normalization
Understanding what is loudness, how it's measured and why standards exist.
Bit depth in digital audio
Understanding bit depth, quantization and why float sample rates are needed.
Audio dithering
How randomization helps to alleviate the effects of quantization.